# 你想知道的关于 DeepSeek 的一切,都在这里!
![]()
# 一、综合类
# 1、DeepSeek 为什么爆火?

一是高性能与低成本的结合:DeepSeek 提供的服务既具备强大的性能又极具性价比,吸引了大量用户和企业采用。
二是DeepSeek 在底层技术优化与创新层面的突破,展示了国内虽然受到非常多的算力封锁,在有限计算资源条件下,也能通过技术创新取得卓越成果。
三是对市场需求的精准把握,例如:AI 平民化、企业级需求、内容生成热潮等。四是以开源吸引开发者,依托开源社区的“自来水”传播,快速建立技术影响力。
五是DeepSeek 的团队成员全部为本土年轻人才,团队研发人员仅 139 名。
# 2、DeepSeek 的市场热度及数据表现如何?
DeepSeek 的用户增长数据和市场接受度表现出色,尤其是在非科技从业者中的普及情况也相当显著。根据Sensor Tower的数据,DeepSeek 应用上线后的前 18 天内获得了1600 万次下载,几乎是 ChatGPT 同期(900 万次)的两倍,已成功登顶140 个国家的应用商店下载排行榜。
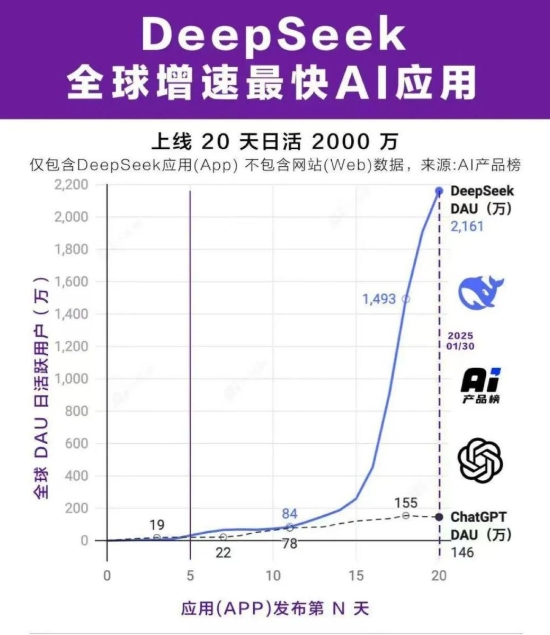
在用户数量方面,DeepSeek 应用上线5 天日活就已超过 ChatGPT 上线同期日活,上线 20 天日活已突破2000万。DeepSeek-R1 跻身 Hugging Face 最受喜爱的模型前十名,下载量超100 万次。微软、百度、华为、天翼等近10 家云平台已宣布上线DeepSeek 大模型。
# 3、DeepSeek 兴起过程中有哪些标志性事件?
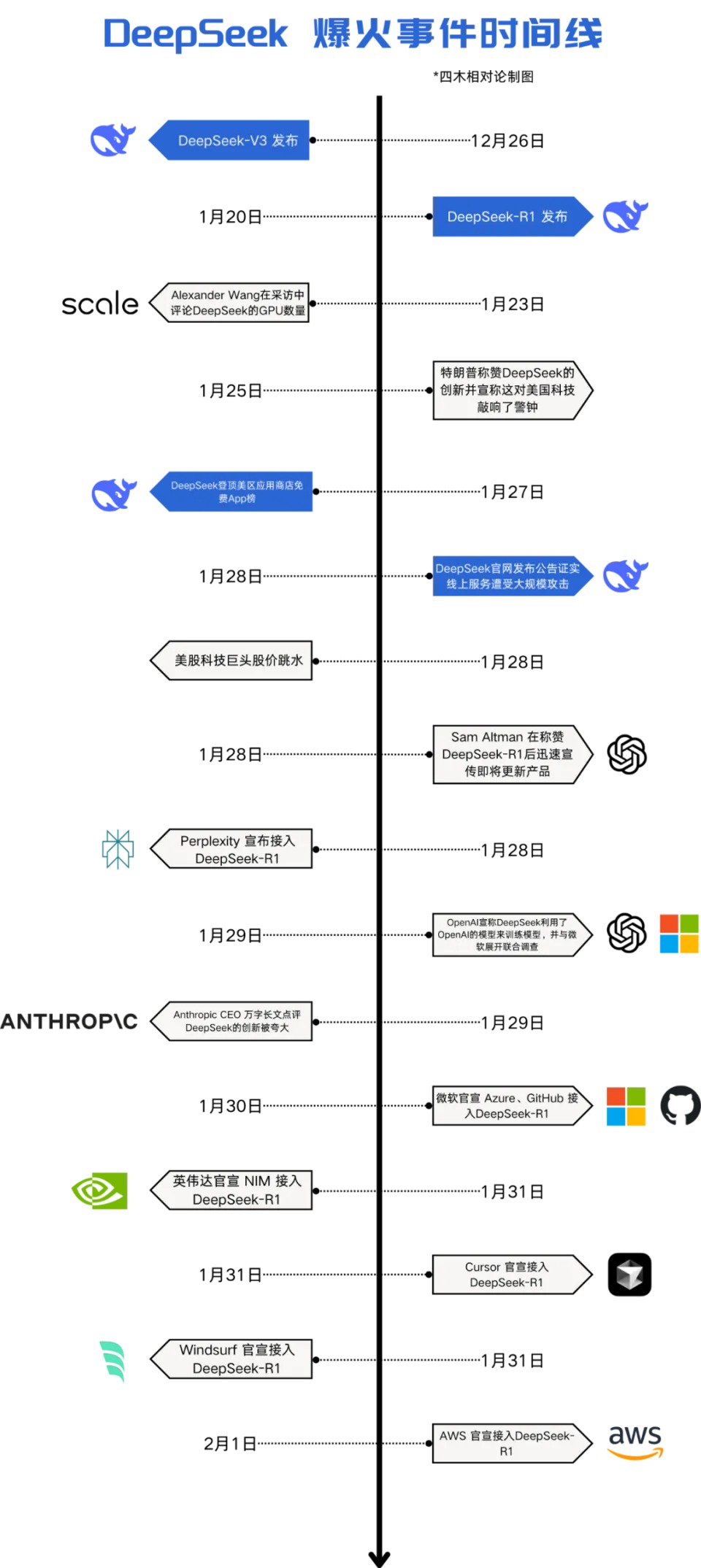
1 月 20 日,DeepSeek 发布开源大模型R1,创始人参加国务院总理会议。
1 月 26 日,DeepSeek 应用登顶苹果应用商店(中国和美国地区)免费 APP 下载榜,《黑神话:悟空》创始人微博推荐,OpenAI CEO 认可其影响力,《纽约时报》称其可与ChatGPT 媲美。
1 月 27 日引发资本市场震动,英伟达股价重挫。
1 月28 日DeepSeek线上服务遭恶意攻击,美官员称其 “偷窃”并调查。
1 月29 日,国际顶刊 Nature(自然)发文,惊叹 DeepSeek-R1 出色的高性能与低成本表现。
# 4、DeepSeek 近期面临哪些主要争议?
一是知识产权与模型训练争议。OpenAI 指控DeepSeek通过“模型蒸馏”技术,不当使用其模型的输出来训练自身系统,涉嫌侵犯知识产权,微软作为 OpenAI 的技术合作伙伴介入调查。DeepSeek否认相关指控,坚称其模型为独立开发。
二是数据隐私与合规性问题。意大利以用户数据可能存储在中国服务器为由,下架其应用。欧洲监管机构也要求其说明是否符合 GDPR(通用数据保护条例)等隐私法规。此外,美国海军以国家安全为由禁止使用DeepSeek 工具,多国政府启动安全审查。
三是商标纠纷。美国公司Delson Group 声称自2020 年已使用“DeepSeek”商标,导致 DeepSeek 在美商标申请受阻。
# 5、DeepSeek-R1 明显的性价比优势对大模型应用意味着什么?
意味着推理模型初步具备规模化应用的基础。R1 将每百万token 的价格从 o1 的 60 美元降至 2.19 美元,近30 倍的价格差异让企业可以更自由地进行 AI 应用实验和创新。

相较于普通用户需要 200 美元订阅费方可随意使用 OpenAI o1,R1 让推理模型普及到大多数人。可以说,规模化应用是科技企业最重要的创新价值。历史上瓦特不是发明蒸汽机,而是让蒸汽机性能大幅提升,可以规模化应用,DeepSeek-R1 引起轰动也有类似原因。
# 6、DeepSeek-R1 是否预示着算力需求将要暴跌?
恰恰相反,长期看 AI 算力需求只会增长。近期由于受到“DeepSeek 冲击”,英伟达公司股价单日下跌17%,市值一日内蒸发近6000 亿美元,创历史单日最大市值损失。
有人认为,低廉的训练成本预示着 AI 大模型对算力投入的需求将大幅下降,可能是英伟达股价大跌的主要原因之一。
历史上,每一次蒸汽机的改进都加速了煤炭的消耗,因为煤炭利用的效率与经济性越高,都导致生产规模的扩大和煤炭需求的增长。
大模型领域也将是如此,DeepSeek-R1 虽然降低了训练成本,但也将推动 AI 大模型的规模化应用,这会进一步放大AI 的各类算力需求。
# 7、DeepSeek 总体对全球 AI 产业格局有什么影响?
首先,打破技术垄断,DeepSeek 作为AI 领域的新势力,打破了美国科技巨头在 AI 领域的绝对领先地位。
其通过优化算法和架构,降低了对高端硬件的依赖,这使得AI 技术的开发不再局限于少数拥有庞大资源的公司,为全球 AI 行业树立了新的标杆。
其次,它的开源策略为行业发展提供了强大的助力。通过开源模型和技术,DeepSeek 让更多的研究人员和企业能够基于其成果进行进一步的研究和开发,促进了技术的共享与创新,加速了AI 技术的普及和应用。
再者,DeepSeek 的成功也为中国 AI 产业赢得了国际声誉,提升了中国在全球 AI 领域的地位。
# 8、DeepSeek 的出现对中美科技竞争带来什么影响?
DeepSeek 的出现引发了美国在AI 领域对中国的进一步限制措施,甚至推动了中美在 AI 领域的“脱钩”。

一方面,美国试图通过立法手段遏制中国 AI 技术的发展。2025 年1 月,美国国会参议员乔什·霍利(Josh Hawley)提出了一项名为《2025 年美国人工智能能力与中国脱钩法案》,该法案的核心内容包括禁止技术交流、限制人员合作、切断投资、刑事处罚等。这将进一步加剧中美在科技领域的竞争。

另一方面,DeepSeek 的成功也显示出中国在AI 领域的快速进步,这可能会促使中国在 AI 领域更加独立自主。未来,全球科技竞争将更加多元化,各国将更加注重在AI 领域的战略布局和技术积累。
# 9、DeepSeek 的崛起对英伟达等硬件厂商带来什么影响?
DeepSeek 的高效模型架构和训练方法,使其在训练和推理过程中对 GPU 需求降低。这种效率提升引发了市场对未来是否需要大规模采购英伟达高端 GPU 的质疑,导致英伟达股价短期内大跌。

同时,DeepSeek-R1 因其高性能并可以部署在华为昇腾等硬件上,这也为 AI 硬件市场带来了更多的选择,进一步削弱了英伟达在GPU市场的垄断地位。此外,AMD 等公司迅速宣布对DeepSeek R1和V3模型提供支持,这表明 DeepSeek 的技术创新正在推动整个AI 硬件市场的竞争格局发生变化,促使硬件厂商不断提升产品性能和服务质量,以适应新的市场需求。
# 二、公司类
# 10、DeepSeek 是一家什么样的公司?
DeepSeek(深度求索)于 2023 年成立,总部位于中国杭州,是一家专注于人工智能基础技术研究的科技公司,致力于探索AGI(通用人工智能)的实现路径。

DeepSeek 核心价值观首先是强调创新驱动,从模型结构等基础层面进行研究,走到技术的前沿,去推动整个生态发展。其次是秉持普惠 AI 的理念,通过降低大模型的 API 价格,推动AI 技术的普及,让更多人能够受益于人工智能。此外,DeepSeek 高度重视开源文化,认为开源不仅能够促进技术的进步,还能为团队带来额外的荣誉和成就感,形成公司的文化吸引力。
# 11、DeepSeek 创始人的背景如何?
DeepSeek 创始人梁文锋 1985 年出生于广东省湛江市,毕业于浙江大学。自 2008 年起,他开始带领团队使用机器学习等技术探索全自动量化交易。

2015 年,成立了杭州幻方科技有限公司,通过数学和人工智能进行量化投资。他带领团队不断创新,推动了量化投资的 AI 化,使幻方量化一度突破千亿级,成为中国量化私募四巨头之一。
2023 年 5 月,梁文锋成立了 DeepSeek 公司,专注于通用人工智能(AGI)的研究与开发。
# 12、DeepSeek 的团队构成如何?
DeepSeek 研发团队规模约 140 人,大多数来自北大、清华等国内顶尖高校,以应届硕博毕业生和年轻研究员为主,本土化程度非常高。团队成员不仅拥有深厚的学术背景,而且多次在国际顶会或竞赛中取得了亮眼成绩。

根据领英网站检索样本发现,DeepSeek 员工85%以上拥有硕士学位,40%以上有博士学位。团队成员平均年龄约为28 岁,90 后占比超 75%,95 后员工占比 50%以上。同时DeepSeek 的员工中也有相当一部分具有交叉学科背景。
# 13、DeepSeek 的薪酬水平如何?
DeepSeek 的薪资采用“一年 14 薪”的模式,即每位员工每年可获得 14 个月的薪资。
DeepSeek 的薪酬水平对标字节跳动公司研发,甚至更高。在 DeepSeek 曾挂出的职位中,大部分岗位的起薪在2 万元以上,并且这些岗位几乎没有经验要求,都面向在校/应届生开放。
年薪最高的职位是“深度学习研究员”,月薪水平为8-11 万元,该职位年薪最高可达税前 154 万元人民币。
“资深UI 设计师”及“深度学习研发工程师”的薪资最高可到 98 万。DeepSeek 还提供高薪实习机会,实习生的日薪为 500-1000 元。
# 14、DeepSeek 有哪些主要产品?

DeepSeek 目前主要的产品包括三大类:
一是DeepSeekV3模型,基本上可以处理绝大多数种类的任务,多项评测成绩接近GPT-4o。
二是 DeepSeek R1 和 DeepSeek R1 Zero 推理模型,R1性能与 GPT o1 不相上下,在需要逻辑推理的任务上更擅长,比如写代码,做数学题。同时 R1 的成本也会更高。
三是Janus-Pro 和JanusFlow系列的多模态模型,其中 Janus-Pro-7B 能够根据文本提示生成图像,其 性 能 与 OpenAI 的 DALL-E 3 以 及Stability AI 的StableDiffusion 相当。
# 15、DeepSeek-V3 凭什么能比肩闭源?
DeepSeek-V3 是一款强大的混合专家(MoE)语言模型,总参数达 671B,每个 token 激活 37B 参数。为实现高效推理和低成本 训 练 , 它 采 用 了 Multi-head Latent Attention (MLA)和DeepSeekMoE 架构。在训练过程中,DeepSeek-V3 进行了大规模的预训练,使用了 14.8 万亿多样且高质量的token。

之后,通过监督微调(SFT)和强化学习(RL)等阶段,充分发挥其性能优势。综合评估显示,DeepSeek-V3 在性能上超越了其他开源模型,与领先的闭源模型相当。更为重要的是,根据官方技术论文,DeepSeek-V3 的总训练成本为 557.6 万美元,相比之下,GPT-4o 等模型的训练成本约为1亿美元。
# 16、DeepSeek-R1 性能是否超越了OpenAI o1?
DeepSeek-R1 性能与 o1 不相上下,在一些任务上甚至表现更优。例如,在 MATH 基准测试中,R1 的准确率达到77.5%,与o1的 77.3% 相近;在 AIME 2024 测试中,R1 的准确率达到71.3%,超过了 o1 的 71.0%;在代码领域,R1 在Codeforces 评测中达到了2441 分的水平,高于 96.3% 的人类参与者。
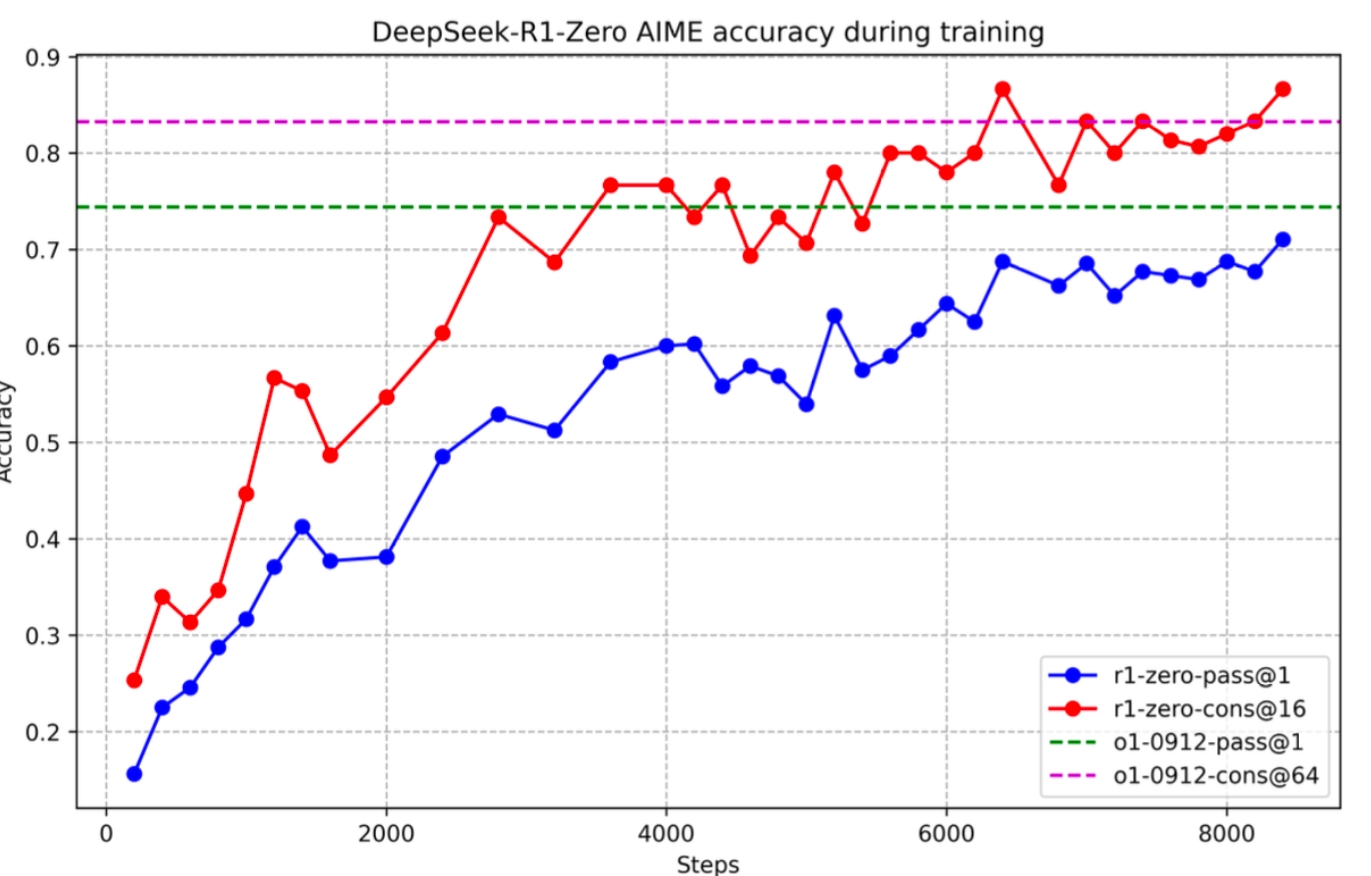
R1 的强大推理能力得益于其独特的训练方式,包括采用纯强化学习训练的R1-Zero以及后续的多阶段训练优化。此外,R1 还具备联网搜索的功能,这使得它在处理需要实时信息的问题时具有明显优势,能够为用户提供更及时、准确的答案。
# 17、DeepSeek 产品的核心优势是什么?
DeepSeek 产品的核心优势在于其以低成本实现了高性能。在训练成本方面,DeepSeek-V3 的训练成本仅为557.6 万美元,相比之下,OpenAI 训练 ChatGPT-4o 的成本高达7800 万美元甚至1亿美元,差距十分显著。在性能表现上,DeepSeek 的模型在多个领域都展现出了卓越的能力。
以 R1 为例,它在推理能力上与OpenAI o1 相当,且在某些任务上超越了 o1。同时,R1 支持联网搜索,这是许多其他推理模型所不具备的功能,使得它在处理时效性问题时更加得心应手。在模型的通用性和灵活性方面,DeepSeek 的模型也表现出色。通过创新的架构设计和训练方法,这些模型能够适应多种不同的任务和场景,无论是数学计算、代码生成、文本创作还是知识问答,都能够提供高质量的答案和解决方案。